


Deploy AI systems that perform and scale reliably. The AI Delivery Engine - Continuous evaluation, built-in guardrails, and monitoring for ML, GenAI, and Agentic AI.

Make sure your AI delivers exactly what you envisioned with Qualifire’s state-of-the-art evaluation, guardrails and controls platform

Obsidian Security delivers complete SaaS security—gain control, stop threats, and ensure compliance across all your business apps.

Unified LLM Observability and AI Agent Evaluation Platform for AI Applications—from development to production.

Release high-quality LLM apps quickly without compromising on testing. Never be held back by the complex nature of LLM interactions.
BIG-bench remains a landmark open-source benchmark suite in late 2025, featuring over 200 diverse tasks that probe reasoning, creativity, social understanding, and more. Though many tasks are now solved by frontier models, its breadth makes it ideal for broad capability assessment and historical comparison—completely free, community-driven, and easy to run.

OpenRouter stands as the leading unified AI model API platform in late 2025, providing seamless access to over 605 models from dozens of providers through a single endpoint. Features like intelligent routing, automatic fallbacks, transparent pricing, and valuable usage analytics make it indispensable for developers seeking reliability and cost efficiency.
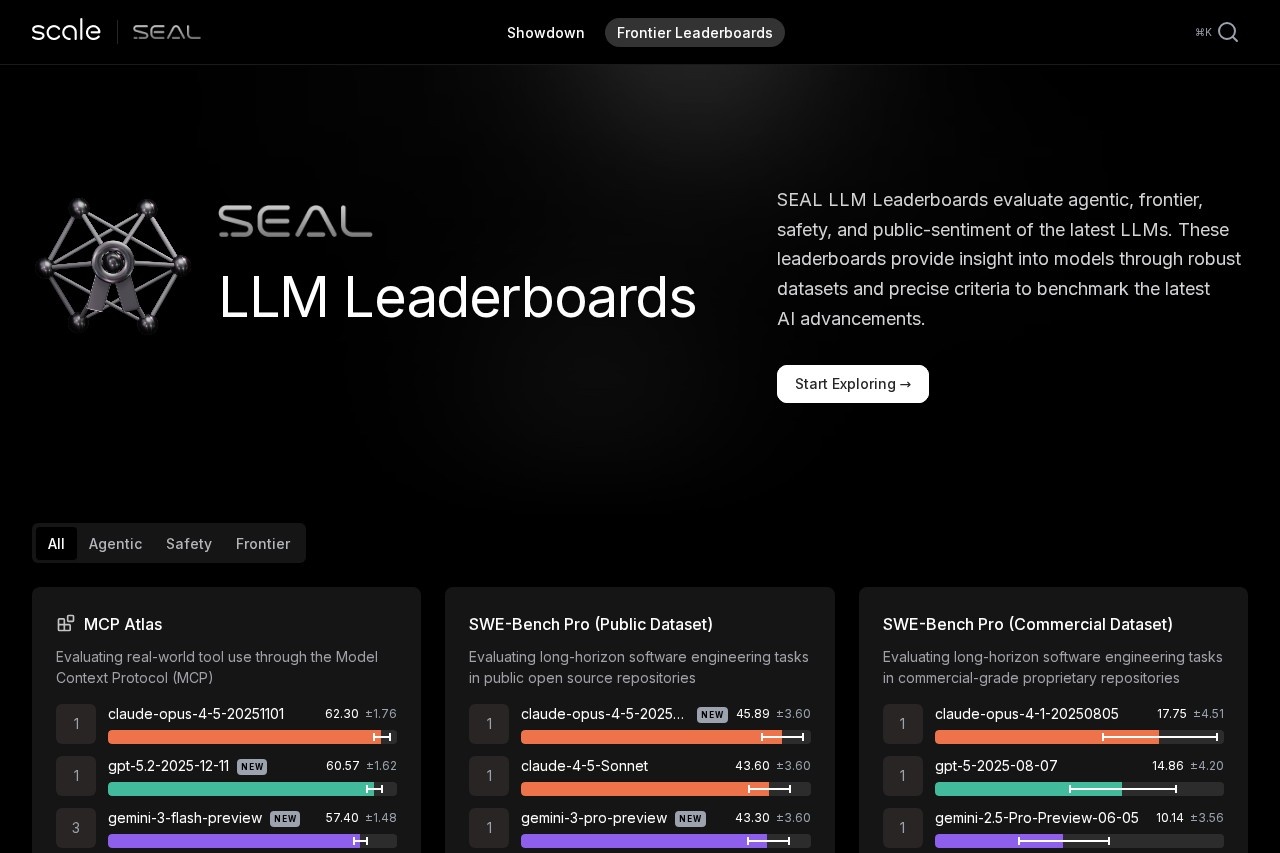
Scale SEAL Leaderboard remains the gold standard for trustworthy LLM rankings in late 2025. Using private datasets to avoid contamination, it rigorously evaluates frontier models across agentic, reasoning, coding, multimodal, and safety benchmarks—Claude Opus 4.5, GPT-5 series, and Gemini 3 Pro consistently lead.

Traceloop excels as the top open-standards LLM observability platform in late 2025, built on OpenLLMetry (OpenTelemetry). It offers instant tracing, automated quality checks, custom evaluators, and deep integrations—ideal for catching issues before production.

Arize Phoenix stands out as the premier open-source LLM observability platform in late 2025. It delivers powerful tracing, interactive embeddings visualization, built-in evaluations, and drift detection—completely free and self-hostable.

Lilac AI excels as an open-source platform for curating unstructured text datasets for LLMs, offering fast clustering, semantic search, PII detection, and concept tagging. Acquired by Databricks in 2024, it integrates seamlessly for enterprise scale—ideal for improving data quality in fine-tuning, RAG, and evaluation workflows.
Giskard AI excels as the top LLM red teaming platform in late 2025, delivering automated vulnerability detection for hallucinations, jailbreaks, biases, and harmful outputs in AI agents. Key strengths include sophisticated attack generation, human-in-the-loop collaborative dashboards, proactive monitoring, and robust enterprise compliance (SOC 2, GDPR, on-premise). Trusted by companies like Michelin and BNP Paribas, it bridges development and security teams effectively. The open-source version offers solid basics for individuals, while Giskard Hub provides advanced automation and team features—ideal for regulated industries deploying production LLM agents.

Comet ML excels in late 2025 as a versatile MLOps platform combining robust experiment tracking with advanced LLM observability through Opik. It delivers real-time visualizations, seamless integrations, prompt optimization, and production monitoring—trusted by innovative teams seeking reproducible workflows.
Fiddler AI stands as the leading unified AI observability platform in late 2025, specializing in monitoring, explaining, and securing ML, LLM, and agentic systems. It provides deep visibility across the full lifecycle with advanced guardrails, root cause analysis, and over 80 metrics—ideal for enterprises building reliable production AI.

Vellum AI remains the premier LLMOps platform in late 2025, providing an end-to-end solution for building, evaluating, deploying, and monitoring production LLM applications. Its visual workflow builder, comprehensive evaluations, git-like versioning, and robust observability set the standard for teams shipping reliable AI products.

METR (Model Evaluation & Threat Research) leads AI safety efforts in late 2025 as a nonprofit evaluating frontier models for catastrophic risks. It focuses on autonomous capabilities, R&D acceleration, and evaluation integrity—publishing transparent reports and developing benchmarks like RE-Bench and MALT.

Geekbench AI remains the leading cross-platform AI benchmark in late 2025, measuring real-world machine learning performance across CPU, GPU, and NPU with precision-specific scores.

MLCommons aims to accelerate AI innovation to benefit everyone. It's philosophy of open collaboration and collaborative engineering seeks to improve AI systems by continually measuring and improving the accuracy, safety, speed and efficiency of AI technologies. We help companies and universities around the world build better AI systems that will benefit society.

LiveBench stands as the leading contamination-free LLM benchmark in late 2025, using regularly refreshed questions from recent sources and objective ground-truth scoring. It challenges top models like GPT-5.1 and Claude 4.5 across reasoning, math, coding, and more—providing fair, reproducible results trusted for research and development.

Open LLM Leaderboard remains the premier community-driven benchmark for open-source large language models in late 2025. It provides transparent rankings across challenging tasks, helping developers and researchers identify top-performing open models reliably.
- Previous Page
- 1
- 2
- 3
- 4
- Total 4 pages

How to Build a $2,500+/Month AI Print-on-Demand Agency in 2026 Using Wan 2.5 + Recraft for Redbubble Sellers
01/17/2026
How to Build a $4,000+/Month AI Print-on-Demand Etsy Agency in 2026 Using Ideogram + iMini AI for POD Sellers & Creators
01/10/2026
Alibaba Drops Qwen3-Omni-Flash: The Lightning-Fast Full-Modal Agent That Sees, Hears, Speaks, and Acts in Real-Time
12/13/2025
ByteDance's TRAE SOLO Lands in China: Free End-to-End AI Coding Agent That Turns Solo Devs into Full-Stack Teams Overnight
12/12/2025
Midjourney v8.5 Unveils "Consistent Identity" Modeling — Unified Character Generation Across Scenes, Styles, and Time
03/12/2026






