Last Updated: December 24, 2025 | Review Stance: Independent testing, includes affiliate links
Quick Navigation
TL;DR - MLCommons 2025 Hands-On Review
MLCommons stands as the leading open AI engineering consortium in late 2025, driving industry-standard benchmarks via MLPerf suites for training, inference, storage, tiny, and more. With 125+ members, it promotes transparent, reproducible AI performance measurement—free to join and participate, delivering immense value for researchers and companies.
MLCommons Review Overview and Methodology
MLCommons is the premier open engineering consortium dedicated to accelerating AI innovation through collaborative benchmarks, datasets, and best practices. This December 2025 review examines its structure, flagship MLPerf benchmarks, recent 2025 results, working groups, and community impact based on official releases, benchmark data, and participation insights.
Founded on principles of open collaboration, MLCommons unites over 125 members from industry, academia, and non-profits to create trusted standards for AI measurement—focusing on performance, safety, efficiency, and affordability.
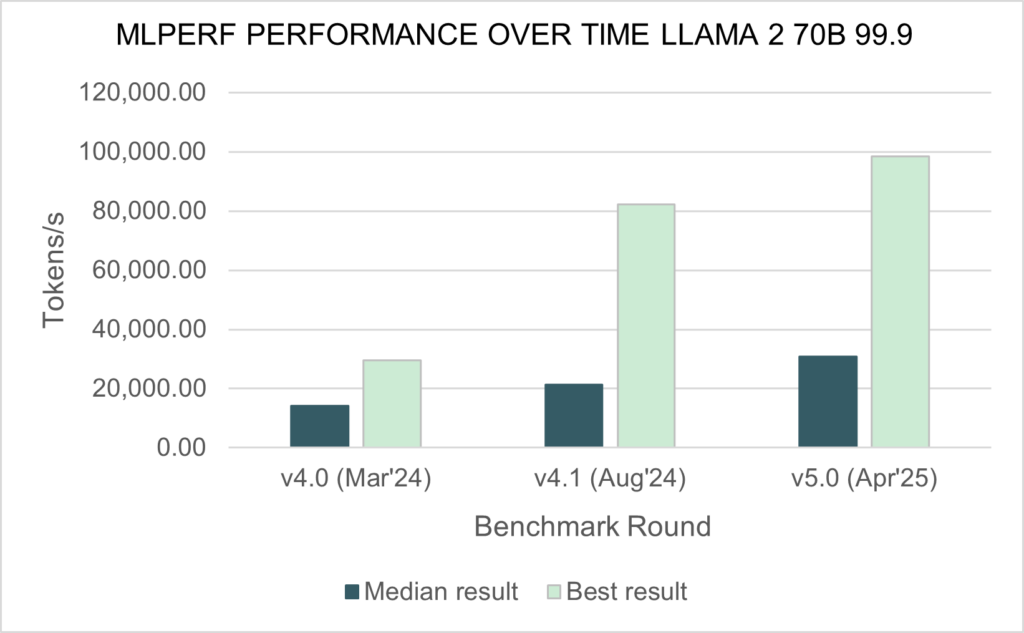
MLCommons MLPerf results evolution (source: MLCommons official)
MLPerf Benchmarks
Industry-standard suites for training/inference performance.
AI Safety & Risk
Working groups for reliable AI standards.
Data Standards
Tools like Croissant for dataset metadata.
Community Collaboration
Open contribution to benchmarks and research.
Core Features of MLCommons
Flagship MLPerf Suites
- Training & Inference: Measure full-system performance for datacenter/edge.
- Storage & Tiny: Specialized for storage bottlenecks and microcontrollers.
- Client & Automotive: Mobile/embedded and ADAS scenarios.
- Power Measurement: Energy efficiency alongside speed.
- Regular updates with new models like Llama 3.1 and Flux.1.
Additional MLCommons Initiatives
- AI Risk & Reliability working group
- Data standards (Croissant format in 700k+ datasets)
- MedPerf for federated medical AI evaluation
- Global governance contributions
MLCommons Benchmarks & 2025 Results
MLCommons drives transparency with record submissions in 2025, showing massive genAI gains and hardware diversity.
Key 2025 MLPerf Highlights
Training v5.1 GenAI Gains
New Llama/Flux Benchmarks
Storage & Tiny Updates
Automotive v0.5
MLCommons Use Cases & Community Involvement
Primary Applications
- Hardware/software vendors submitting MLPerf results
- Researchers comparing AI system performance
- Companies procuring AI infrastructure
- Contributing to safer AI standards
Member Benefits
Benchmark Submissions
Working Groups
Data Standards
Global Influence
MLCommons Membership, Access & Value
Open Participation
Free for all
Individuals & academics
✓ Full Access
Contribute freely
Organizational Membership
Dues-based tiers
Voting & leadership
Influence Standards
All benchmarks and tools free as of December 2025; membership dues fund operations for organizations.
MLCommons Value Proposition
Benefits
- Industry-standard credibility
- Transparent comparisons
- Community-driven evolution
- Influence on AI safety
Participation
- Submit results
- Join working groups
- Contribute code/data
Pros & Cons: Balanced MLCommons Assessment
Strengths
- Gold-standard MLPerf benchmarks
- Broad industry/academia collaboration
- Rapid evolution with new workloads
- Focus on safety and data standards
- Transparent, reproducible results
- Free for individual participation
Considerations
- Membership dues for organizations
- Benchmark complexity for newcomers
- Focus mainly on performance metrics
- Submission process rigor
- Evolving scope may fragment efforts
Who Should Join MLCommons?
Perfect For
- AI hardware/software vendors
- ML researchers & academics
- Companies procuring AI systems
- AI safety advocates
Consider Alternatives If
- Only need simple benchmarks
- Prefer proprietary testing
- Focused solely on non-performance metrics
- Very limited resources
Final Verdict: 9.6/10
MLCommons has solidified its role in 2025 as the essential consortium for trustworthy AI benchmarks and standards. MLPerf's breadth, community drive, and real-world impact make participation invaluable for advancing transparent, high-performance AI development.
Community: 9.7/10
Impact: 9.5/10
Accessibility: 9.3/10
Ready to Shape the Future of AI Benchmarks?
Join the MLCommons community or explore the latest MLPerf results today.
Open collaboration as of December 2025.