

Tongyi Bailong's Speech Twins Go Open-Source: Alibaba Drops Upgraded Fun-CosyVoice3 and Fun-ASR — 3-Second Voice Cloning Across 9 Languages and 18 Dialects
On December 15, 2025, Alibaba's Tongyi Lab unleashed major upgrades to its Bailong speech twins — Fun-CosyVoice3 (TTS) and Fun-ASR (speech recognition) — while simultaneously open-sourcing lightweight versions like Fun-CosyVoice3-0.5B and Fun-ASR-Nano-0.8B. The star feature? Zero-shot voice cloning from just 3 seconds of audio, seamlessly switching across 9 languages, 18 Chinese dialects, and 9 emotions with uncanny fidelity. Latency slashed by 50%, noisy environment accuracy hitting 93%, and full local deployment support — this duo crushes rivals like ElevenLabs and Whisper in multilingual realism, flooding ModelScope and Hugging Face with instant downloads.

NVIDIA Unleashes Nemotron 3 Series: Open-Source Powerhouse Delivers 4x Throughput, Rewriting the Rules for Agentic AI at Scale
NVIDIA launched the Nemotron 3 family of open models on December 15, 2025 — starting with Nemotron 3 Nano (30B params) available immediately, followed by Super and Ultra in early 2026. Powered by a breakthrough hybrid Mamba-Transformer MoE architecture, Nano achieves 4x higher token throughput than Nemotron 2 Nano while slashing reasoning tokens by up to 60%. With native 1M-token context, open weights, datasets (3T tokens), and RL libraries, this series arms developers for transparent, efficient multi-agent systems — early adopters like Palantir, Perplexity, and ServiceNow are already deploying it to crush costs and boost intelligence.

LiblibAI Launches Wan 2.6: China's Answer to Sora 2 — Multi-Shot Storytelling, Voice-to-Video Sync, and 15-Second Cinematic Clips in One Go
On December 14, 2025, LiblibAI became the first platform worldwide to roll out Alibaba Tongyi Wanxiang's Wan 2.6 video generation model. Dubbed the "Chinese Sora 2," it introduces groundbreaking video-reference generation, perfect audio-visual synchronization, and intelligent multi-shot scheduling — outputting seamless 15-second 1080P narratives without post-editing. Supporting single/multiple performers, lip-synced dialogue, and reference-based character replication, Wan 2.6 catapults user-generated shorts to pro levels, with early clips flooding social feeds and slashing production time by 80%.
Double Drop: Figma's AI Image Editing Suite & Google's Selfie-Powered Virtual Try-On Reshape Design and Shopping Forever
December 2025 delivered a one-two punch to creative and commerce workflows: Figma rolled out three precision AI image editing tools — Erase Object, Isolate Object, and Expand Image — on December 10, letting designers lasso and refine visuals without ever leaving the canvas. Days later, on December 11, Google upgraded its virtual try-on with Nano Banana AI, generating full-body digital models from a single selfie for realistic clothing previews, now live for U.S. shoppers. These launches slash friction in design pipelines and online retail, proving AI isn't just generating — it's perfecting the human touch.
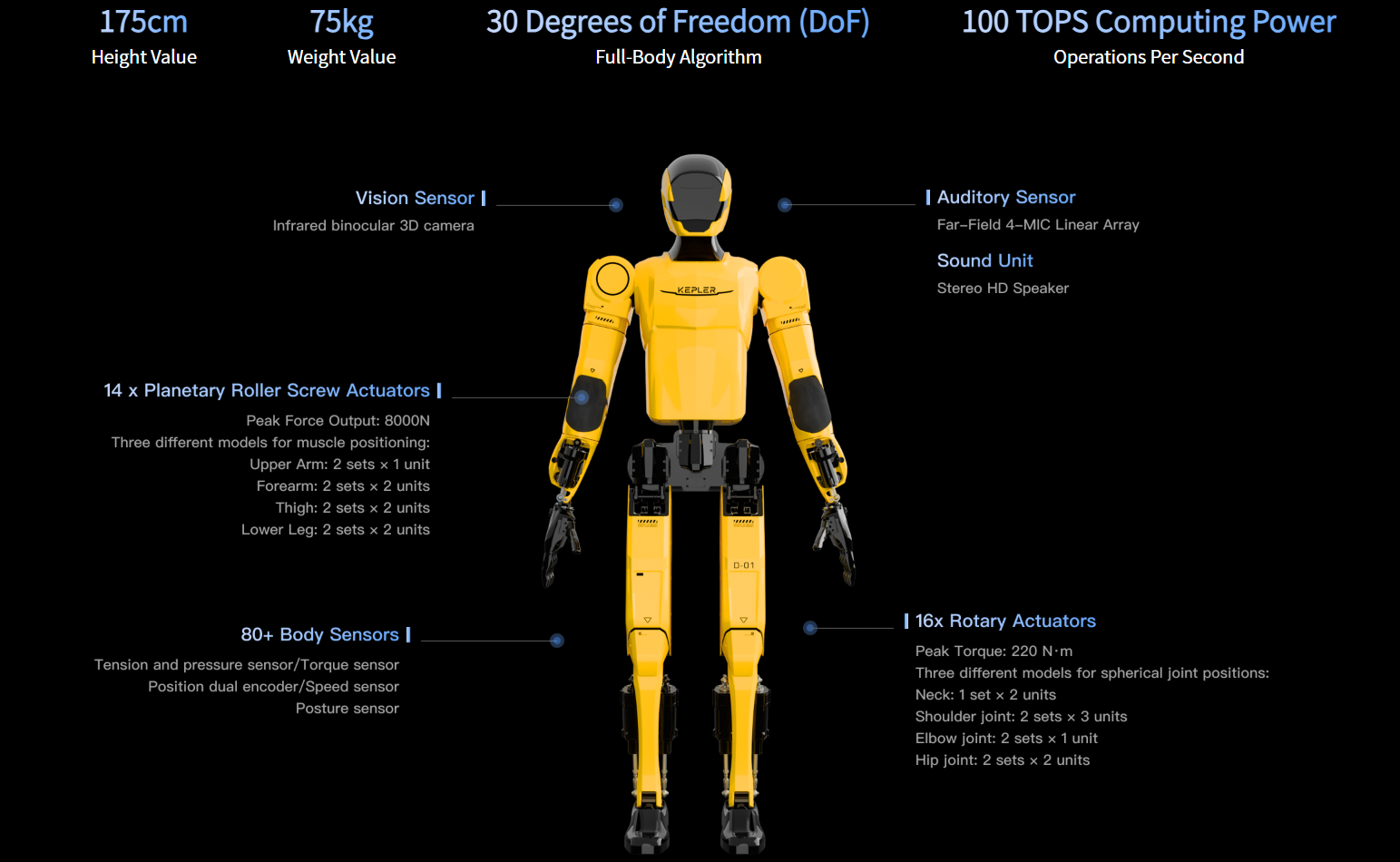
Kepler Robotics Begins Delivery of K2 Humanoid: The 75kg "Bumblebee" Built for Factory Floors, With 30kg Dual-Arm Payload and 8-Hour Endurance
Shanghai-based Kepler Robotics has started delivering its flagship K2 humanoid robot — nicknamed "Bumblebee" — following mass production kickoff in September 2025. Weighing 75kg with a dual-arm payload of 30kg (15kg per arm), it charges in one hour for up to eight hours of continuous operation. The first batches are heading to automotive manufacturing lines, where early tests show 1.5x human efficiency in material handling and assembly. With thousands of intent orders already secured, Kepler is accelerating China's push toward "humanoid factory workers" in the 2025 mass-production era.
GPT-5.2 Officially Released: OpenAI's Agentic Beast That Promises to Slash Office Work by 10 Hours a Week
OpenAI launched GPT-5.2 on December 13, 2025 — its most agentic model yet, with native multi-step planning, persistent memory across sessions, and seamless integration into productivity suites. Early enterprise pilots report average knowledge workers saving 10+ hours weekly on repetitive tasks like email triage, report drafting, meeting summaries, and code reviews. Now rolling out to ChatGPT Plus/Pro/Team users, GPT-5.2 marks the shift from "helpful assistant" to "autonomous coworker."

Zhipu AI Wraps Multimodal Open Source Week: Four Core Video Generation Technologies Fully Open-Sourced — Paving the Way for Next-Gen AI Filmmaking
On December 13, 2025, Zhipu AI concluded its "Multimodal Open Source Week" with a bang — open-sourcing four pivotal technologies powering advanced video generation: GLM-4.6V for visual understanding, AutoGLM for intelligent device control, GLM-ASR for high-fidelity speech recognition, and GLM-TTS for expressive speech synthesis. These modules, now freely available on GitHub and Hugging Face, enable end-to-end multimodal pipelines that fuse perception, reasoning, audio, and action — slashing barriers for developers building interactive video agents, embodied AI, and cinematic tools.

Google Drops Gemini Deep Research Agent: SOTA on Tough Benchmarks, Open-Sources DeepSearchQA to Challenge the Field
Google unleashed an upgraded Gemini Deep Research agent on December 11, 2025 — powered by Gemini 3 Pro and now accessible via the new Interactions API for developers. This autonomous research beast iteratively plans, searches deep into sites, fills knowledge gaps, and synthesizes cited reports, hitting SOTA scores like 46.4% on Humanity’s Last Exam (beating GPT-5 Pro's 38.9%) and 66.1% on the newly open-sourced DeepSearchQA benchmark. Priced at roughly 1/10th of rivals, it's Google's bold play to embed industrial-grade research into apps while democratizing agent evaluation.

Zhipu AI Open-Sources GLM-TTS: Multi-Reward RL-Powered TTS That Clones Voices in 3 Seconds with Emotional Depth
Zhipu AI released and open-sourced GLM-TTS on December 11, 2025 — an industrial-grade text-to-speech system that clones any voice from just 3 seconds of audio, delivering natural prosody, emotional expressiveness, and precise pronunciation. Powered by a two-stage architecture and multi-reward reinforcement learning (GRPO framework), it hits open-source SOTA on character error rate (0.89%) and emotional fidelity using only 100K hours of training data. Weights are now available on GitHub and Hugging Face, with seamless integration into Zhipu's ecosystem for audiobooks, assistants, and dubbing.
MiniMax's VoxCPM 1.5 Goes Open-Source: Voice Generation Gets a Massive Upgrade — Natural, Emotional, and Fully Controllable
On December 12, 2025, MiniMax (FaceWall Intelligence) open-sourced VoxCPM 1.5 — its next-gen text-to-speech model that leaps forward in naturalness, emotional depth, and fine-grained control. Supporting multilingual synthesis, prosody adjustment, and zero-shot voice cloning, it outperforms ElevenLabs and XTTS v2 on blind tests while staying fully open-weights. Now live on GitHub and Hugging Face, early adopters are already deploying it for audiobooks, dubbing, and real-time voice agents.

Alibaba Drops Qwen3-Omni-Flash: The Lightning-Fast Full-Modal Agent That Sees, Hears, Speaks, and Acts in Real-Time
Alibaba Cloud unveiled Qwen3-Omni-Flash on December 12, 2025 — the industry's first production-ready full-modal agent model that natively fuses vision, audio, text, and action in a blazing-fast 8B-parameter package. Running at 300+ tokens/sec on consumer GPUs, it powers real-time screen understanding, live voice interaction, desktop automation, and multimodal reasoning without separate encoders or pipelines. Now live on Tongyi Qianwen app and DashScope API, early enterprise users report 6x faster agent workflows, positioning Alibaba to dominate the emerging "omniverse agent" era.
Adobe Teams Up with ChatGPT: Photoshop, Express, and Acrobat Now Live Inside the Chat — Conversational Editing Just Killed App-Switching Hell
On December 10, 2025, Adobe launched native integrations for Photoshop, Adobe Express, and Acrobat directly into ChatGPT — bringing pro-grade image editing, graphic design, and PDF management to the platform's 800 million weekly users. Describe your edits in plain words ("blur the background" or "merge these PDFs"), upload files, and watch real-time magic happen with sliders, effects, and drag-and-drop interfaces — all free, no subscriptions needed for core features. Early feedback: creators slashing workflow time by 70%, with seamless upsell paths to full Adobe apps.







