

Google Drops Gemini Deep Research Agent: SOTA on Tough Benchmarks, Open-Sources DeepSearchQA to Challenge the Field
Google unleashed an upgraded Gemini Deep Research agent on December 11, 2025 — powered by Gemini 3 Pro and now accessible via the new Interactions API for developers. This autonomous research beast iteratively plans, searches deep into sites, fills knowledge gaps, and synthesizes cited reports, hitting SOTA scores like 46.4% on Humanity’s Last Exam (beating GPT-5 Pro's 38.9%) and 66.1% on the newly open-sourced DeepSearchQA benchmark. Priced at roughly 1/10th of rivals, it's Google's bold play to embed industrial-grade research into apps while democratizing agent evaluation.

Zhipu AI Open-Sources GLM-TTS: Multi-Reward RL-Powered TTS That Clones Voices in 3 Seconds with Emotional Depth
Zhipu AI released and open-sourced GLM-TTS on December 11, 2025 — an industrial-grade text-to-speech system that clones any voice from just 3 seconds of audio, delivering natural prosody, emotional expressiveness, and precise pronunciation. Powered by a two-stage architecture and multi-reward reinforcement learning (GRPO framework), it hits open-source SOTA on character error rate (0.89%) and emotional fidelity using only 100K hours of training data. Weights are now available on GitHub and Hugging Face, with seamless integration into Zhipu's ecosystem for audiobooks, assistants, and dubbing.
MiniMax's VoxCPM 1.5 Goes Open-Source: Voice Generation Gets a Massive Upgrade — Natural, Emotional, and Fully Controllable
On December 12, 2025, MiniMax (FaceWall Intelligence) open-sourced VoxCPM 1.5 — its next-gen text-to-speech model that leaps forward in naturalness, emotional depth, and fine-grained control. Supporting multilingual synthesis, prosody adjustment, and zero-shot voice cloning, it outperforms ElevenLabs and XTTS v2 on blind tests while staying fully open-weights. Now live on GitHub and Hugging Face, early adopters are already deploying it for audiobooks, dubbing, and real-time voice agents.

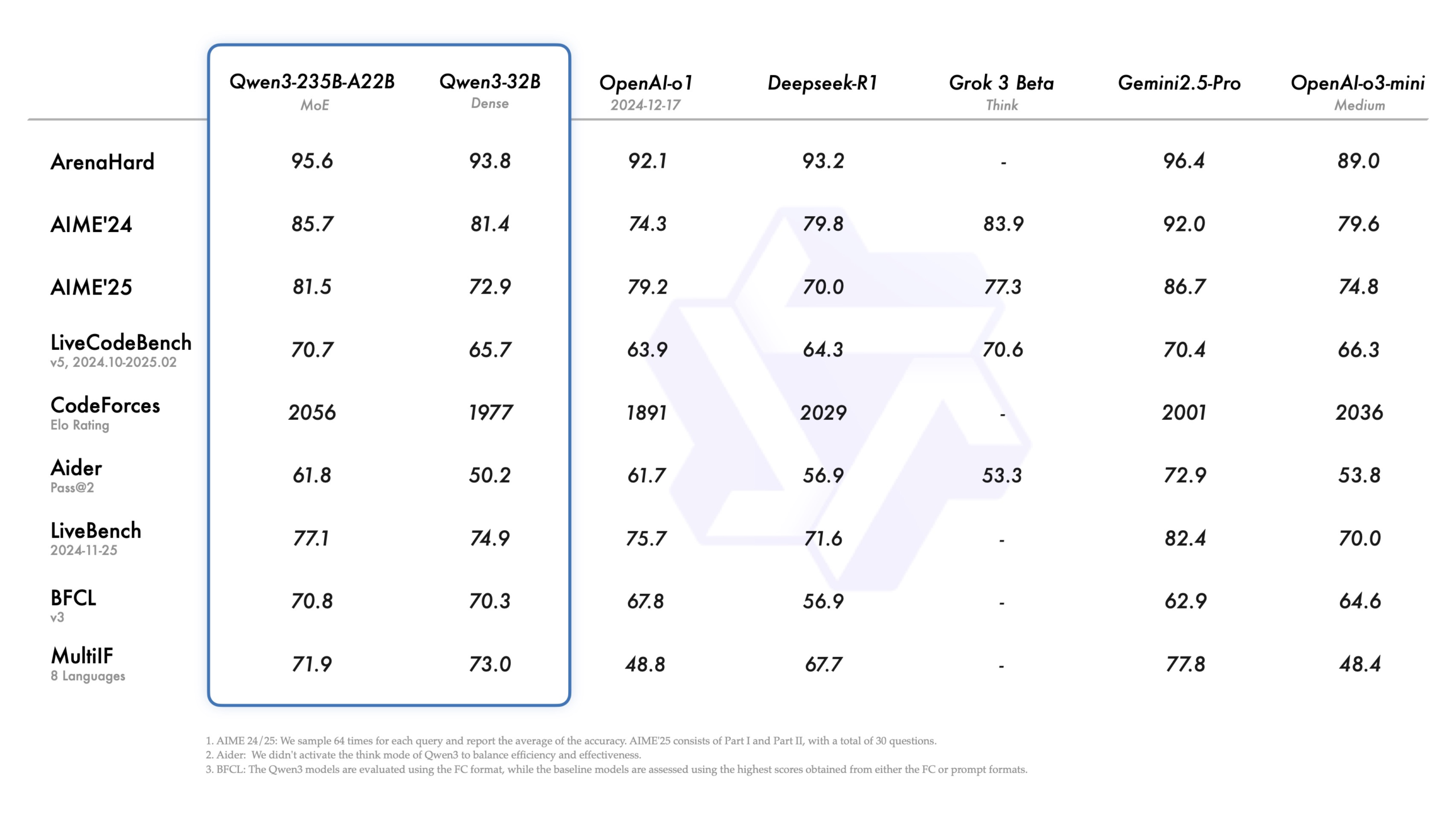
Alibaba Drops Qwen3-Omni-Flash: The Lightning-Fast Full-Modal Agent That Sees, Hears, Speaks, and Acts in Real-Time
Alibaba Cloud unveiled Qwen3-Omni-Flash on December 12, 2025 — the industry's first production-ready full-modal agent model that natively fuses vision, audio, text, and action in a blazing-fast 8B-parameter package. Running at 300+ tokens/sec on consumer GPUs, it powers real-time screen understanding, live voice interaction, desktop automation, and multimodal reasoning without separate encoders or pipelines. Now live on Tongyi Qianwen app and DashScope API, early enterprise users report 6x faster agent workflows, positioning Alibaba to dominate the emerging "omniverse agent" era.
Adobe Teams Up with ChatGPT: Photoshop, Express, and Acrobat Now Live Inside the Chat — Conversational Editing Just Killed App-Switching Hell
On December 10, 2025, Adobe launched native integrations for Photoshop, Adobe Express, and Acrobat directly into ChatGPT — bringing pro-grade image editing, graphic design, and PDF management to the platform's 800 million weekly users. Describe your edits in plain words ("blur the background" or "merge these PDFs"), upload files, and watch real-time magic happen with sliders, effects, and drag-and-drop interfaces — all free, no subscriptions needed for core features. Early feedback: creators slashing workflow time by 70%, with seamless upsell paths to full Adobe apps.

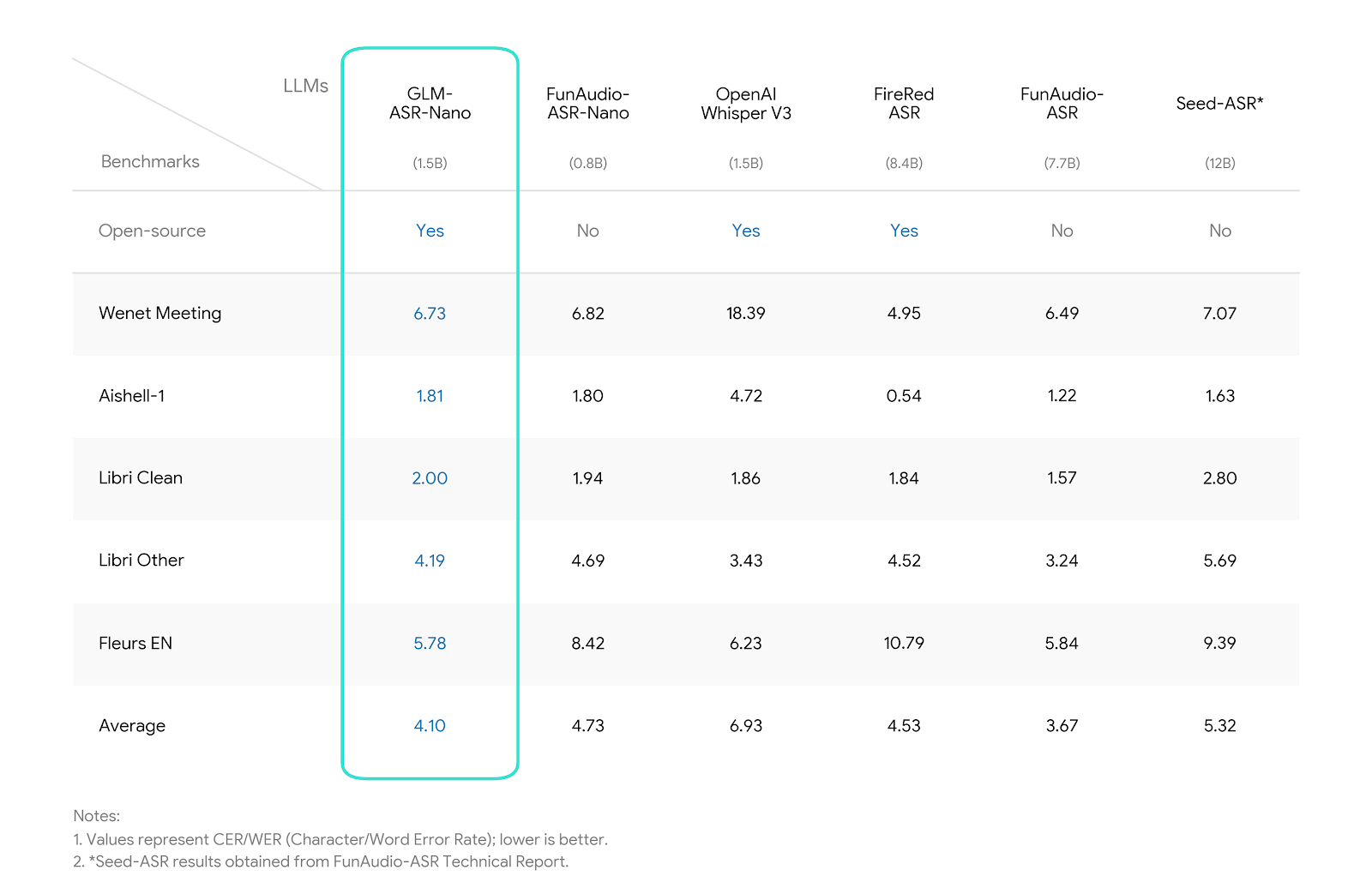
Zhipu AI Drops GLM-ASR Open Source and Launches Intelligent Input Method: Real-Time Voice-to-Text That Thinks Like a Human
On December 12, 2025, Zhipu AI simultaneously open-sourced GLM-ASR — a bilingual streaming speech recognition model with 96.8% accuracy on Mandarin and 98.2% on English — and launched the GLM Intelligent Input Method app. The input method integrates live ASR, semantic prediction, and GLM-4 reasoning, enabling voice dictation that auto-corrects context, completes sentences, and even rewrites in formal tone. Within hours of release, the app topped China's iOS productivity charts, with GLM-ASR's GitHub repo exploding to 15k stars overnight.
Mistral AI Open-Sources Devstral 2: The Next-Gen Agentic Coding Model That Crushes SWE-Bench and Powers Vibe CLI Autonomy
Mistral AI unleashed Devstral 2 on December 9, 2025 — a groundbreaking open-weight coding model family featuring the flagship 123B-parameter Devstral 2 and the compact 24B Devstral Small 2. With a massive 256K context window, SOTA 72.2% on SWE-Bench Verified, and seamless tool-calling for multi-file edits, it outpaces larger rivals at a fraction of the cost. Paired with the open-source Mistral Vibe CLI — a terminal agent that scans codebases, executes changes, and vibes with your workflow — this duo democratizes enterprise-grade agentic coding, from local laptops to cloud fleets.

Zhipu AI Open-Sources AutoGLM: The Phone Agent Framework That Turns Every Smartphone into a True AI Phone
On December 9, 2025, Zhipu AI (Z.ai) fully open-sourced AutoGLM — the groundbreaking open-source phone agent model and framework capable of autonomously operating Android devices via natural language commands. Powered by the AutoGLM-Phone-9B multimodal model, it interprets screenshots, plans multi-step actions, and executes taps, swipes, and inputs across 50+ popular Chinese apps like WeChat, Taobao, Douyin, and Meituan. Deployable locally or in the cloud via ADB, this release democratizes "AI phone" capabilities, challenging closed ecosystems and enabling developers to build privacy-focused agents on any device.

Ant Group's Lingguang AI Assistant Launches Web Version: 30-Second Natural Language App Generation Now Seamless Across Devices
Ant Group officially rolled out the web version of its multimodal general AI assistant Lingguang on December 9, 2025 — completing its multi-device ecosystem and bringing PC users the full power of "Lingguang Dialogue" and "Lingguang Flash Apps." Retaining the signature "30-second natural language mini-app generation" capability, the browser-based experience syncs data and creations with mobile, focusing on workplace and education productivity. Gray tests show heavy usage in professional scenarios, with over 3.3 million flash apps created in the first two weeks post-mobile launch — signaling Lingguang's explosive shift from chat tool to true productivity powerhouse.
Zhipu AI Launches and Open-Sources GLM-4.6V Series: Native Multimodal Tool Calling Turns Vision into Action — The True Agentic VLM Revolution
On December 8, 2025, Zhipu AI officially released and fully open-sourced the GLM-4.6V series multimodal models, including the high-performance GLM-4.6V (106B total params, 12B active) and the lightweight GLM-4.6V-Flash (9B). Featuring groundbreaking native multimodal function calling — where images serve directly as parameters and results as context — plus a 128K token window for handling 150-page docs or hour-long videos, it achieves SOTA on 30+ benchmarks at comparable scales. API prices slashed 50%, Flash version free for commercial use, weights and code now on GitHub/Hugging Face — igniting a frenzy for visual agents in coding, shopping, and content creation.

Tencent Unleashes Hunyuan 2.0: 406B MoE Powerhouse with Industry-Leading Reasoning Efficiency and 256K Context Mastery
Tencent officially launched Hunyuan 2.0 (Tencent HY 2.0) on December 5, 2025 — featuring dual variants: HY 2.0 Think for deep reasoning and HY 2.0 Instruct for rapid responses. Built on a massive 406B-parameter MoE architecture (32B active), it supports 256K context windows while delivering top-tier inference speed and efficiency. Already live in Yuanbao and ima apps, with Tencent Cloud APIs open, early benchmarks show massive gains in math, science, coding, and long-context tasks — positioning it as a domestic frontrunner against global giants.

Google Opens Public Beta for Gemini 3 Deep Think: The "Olympiad Gold Medal-Level" Reasoning Mode That Turns AI into a True Thinking Partner
On December 4, 2025, Google officially rolled out Gemini 3 Deep Think mode in public beta to Google AI Ultra subscribers — building on the Gemini 3 Pro launch last month, this enhanced reasoning engine leverages parallel hypothesis exploration to achieve unprecedented performance on PhD-level science, math olympiad-caliber logic, and long-horizon planning. Inheriting the gold-medal prowess from its Gemini 2.5 predecessors at IMO and ICPC, Deep Think scores 41% on Humanity’s Last Exam (without tools) and 45.1% on ARC-AGI-2, marking the first time an AI publicly demonstrates "deep deliberation" at scale. Early testers report 4x deeper insights on complex queries, cementing Gemini's frontier lead.







