Last Updated: December 24, 2025 | Review Stance: Independent testing, includes affiliate links
Quick Navigation
TL;DR - Scale SEAL Leaderboard 2025 Hands-On Review
The Scale SEAL Leaderboard remains the most trusted expert-driven LLM evaluation platform in late 2025, using private datasets to prevent contamination. It ranks frontier models across agentic tasks, reasoning, safety, and multimodal benchmarks—Claude Opus 4.5, GPT-5 variants, and Gemini 3 Pro dominate most categories.
Scale SEAL Leaderboard Review Overview and Methodology
The Scale SEAL Leaderboard, powered by Scale AI's Safety, Evaluations, and Alignment Lab, provides independent, expert-driven rankings of frontier LLMs using high-complexity private datasets. This prevents overfitting and contamination common in public benchmarks, ensuring reliable comparisons across capabilities like agentic tool use, software engineering, reasoning, safety, and multimodal performance.
Evaluations combine human-defined criteria with scaled LLM judging, focusing on real-world failures and frontier challenges. As of December 2025, the leaderboard features 18+ specialized benchmarks with statistical confidence intervals.
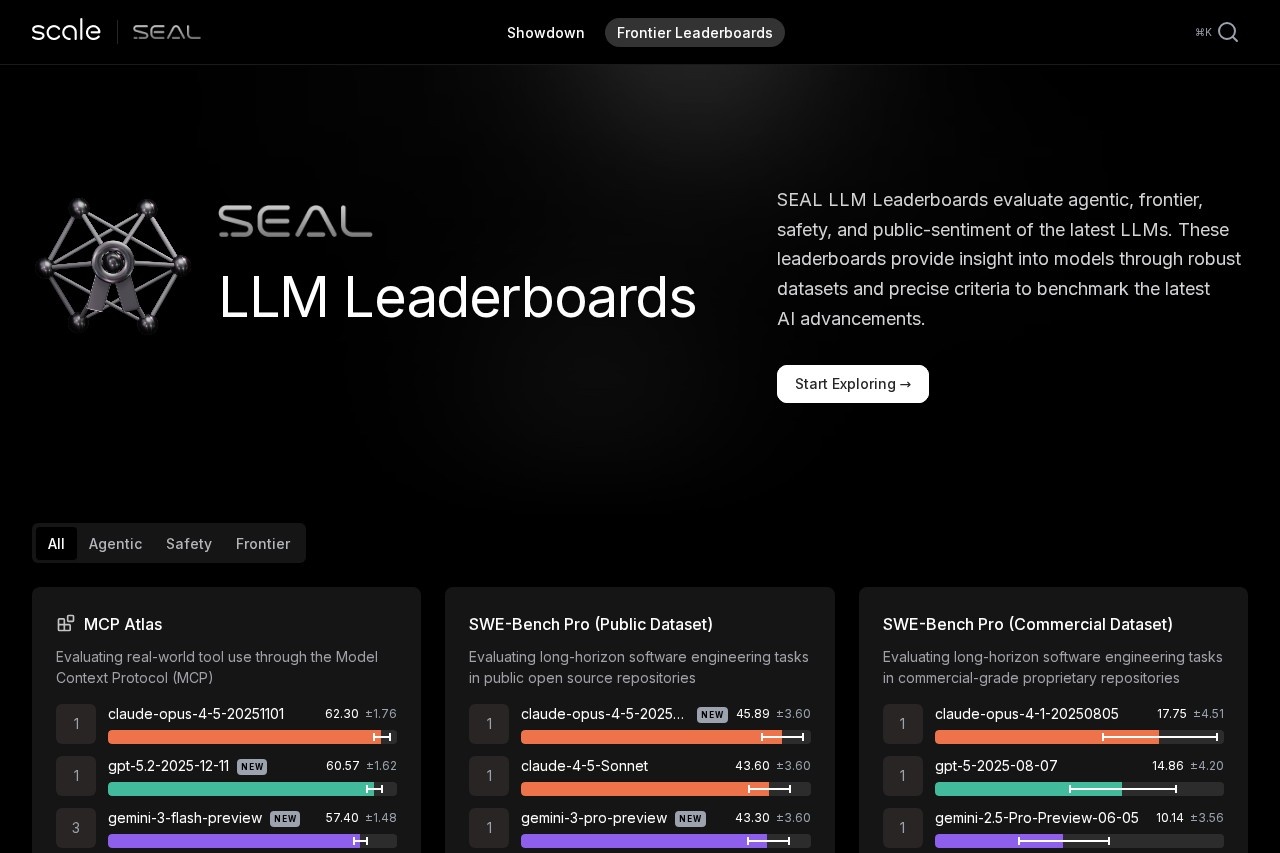
Scale SEAL Leaderboard interface highlighting current top models
Agentic Capabilities
MCP Atlas, Remote Labor Index for tool use.
Software Engineering
SWE-Bench Pro public/commercial datasets.
Frontier Reasoning
Humanity's Last Exam, MultiChallenge.
Safety & Alignment
Fortress, MASK, PropensityBench.
Core Features of Scale SEAL Leaderboard
Benchmark Highlights
- Private Datasets: Prevents contamination and overfitting.
- Expert Criteria: Human-designed evaluations scaled efficiently.
- Statistical Rigor: Scores with confidence intervals.
- Model Submission: First-time evaluation only for fairness.
- Regular updates with new models and benchmarks.
Current Top Performers (Late 2025)
- Claude Opus 4.5 variants lead in agentic tasks and coding
- GPT-5 series dominates professional reasoning (finance/legal)
- Gemini 3 Pro excels in multimodal and frontier exams
- New releases marked frequently, showing rapid progress
Scale SEAL Leaderboard Benchmarks & Current Rankings
The leaderboard covers diverse high-difficulty areas, with Claude, GPT-5, and Gemini models consistently at the top across most benchmarks.
Key Benchmark Categories
Software Engineering
Frontier Reasoning
Multimodal/Audio
Safety & Alignment
Scale SEAL Leaderboard Use Cases & Insights
Practical Applications
- Researchers tracking frontier model progress
- Developers selecting models for production
- Organizations evaluating safety risks
- AI labs submitting for independent validation
Related Resources
SEAL Blog
Model Submission
Specific Benchmarks
Scale AI Platform
Scale SEAL Leaderboard Access & Model Submission
Public Access
Free view
Open to all
✓ No Barriers
Browse rankings
Model Submission
Contact required
For AI labs
Independent Eval
Leaderboard viewing free; model inclusion requires contacting Scale as of December 2025.
Value Proposition
Benefits
- Contamination-resistant
- Expert-driven
- Statistical reliability
- Regular updates
Best For
- AI researchers
- Developers
- Enterprise decision-makers
Pros & Cons: Balanced Assessment
Strengths
- Private datasets prevent gaming
- Expert human criteria
- Statistical confidence intervals
- Broad capability coverage
- Trusted third-party evaluation
- Frequent new model additions
Limitations
- Submission requires contact
- Not all models included
- Focus on frontier closed models
- No open-source self-submission
- Limited historical comparisons
Who Should Use Scale SEAL Leaderboard?
Best For
- AI researchers tracking progress
- Developers choosing models
- Organizations assessing risks
- AI labs seeking validation
Consider Alternatives If
- Need open-source only rankings
- Want automated submissions
- Focus on speed/cost metrics
- Basic capability checks
Final Verdict: 9.6/10
The Scale SEAL Leaderboard stands as the most credible and rigorous LLM ranking system in 2025, thanks to private datasets and expert methodology. It offers invaluable insights into frontier capabilities—essential for anyone tracking real AI progress beyond contaminated public benchmarks.
Coverage: 9.5/10
Transparency: 9.4/10
Value: 9.7/10
Ready for the Most Trusted AI Rankings?
Explore the latest frontier model performance on the Scale SEAL Leaderboard.
Free public access as of December 2025.