

ByteDance Quietly Rolls Out Seedance 2.0 Globally After Copyright Controversy, Now Available Across Multiple Regions
ByteDance has quietly resumed the global rollout of its AI video generation model Seedance 2.0, making it available to users across Africa, South America, the Middle East, and Southeast Asia through CapCut's Dreamina platform. The launch, confirmed on March 26, 2026, comes after the company paused its initial mid-March global release following intense pressure from Hollywood studios over copyright concerns. The controversy erupted when viral AI-generated clips featuring Tom Cruise and Brad Pitt fighting demonstrated the model's ability to create realistic depictions of real celebrities without consent. In response, ByteDance has implemented new safeguards including a ban on uploading images of real people. Seedance 2.0 supports multimodal inputs including text, images, audio, and video, capable of generating up to 15-second clips at 2K resolution with native audio. The phased rollout initially targets markets including Indonesia, Philippines, Thailand, Vietnam, Malaysia, Brazil, and Mexico.

MiniMax Launches Token Plan: World's First Subscription for Full-Modal AI Models
Chinese AI company MiniMax launches Token Plan subscription plan, becoming the world's first unified subscription service that supports full modal models. This plan covers five major modes: text, voice, video, image, and music. The monthly fee starts at $10 and provides M2.7-high high-speed inference services with a throughput of 100 TPS.

DeepSeek V4 Nears Release: Engram Memory Architecture and mHC Technology Explained
Chinese AI company DeepSeek is about to release its fourth generation big model V4, introducing revolutionary Engram memory architecture and mHC (manifold constrained hyperconnectivity) technology. The new model adopts a sparse MoE architecture, supports 1 million token context windows, reduces memory usage by 40%, improves inference speed by 1.8 times, and natively supports multimodal generation of text, images, and videos.

Kimi AI Assistant Silently Upgrades to K2.5 — Moonshot AI's Quiet Revolution in Chinese AI
Moonshot AI has quietly rolled out a significant upgrade to its popular Kimi AI assistant, updating the underlying model to version K2.5. This silent release brings substantial improvements in reasoning, long-context processing, and multimodal capabilities, reinforcing Kimi's position as one of China's leading AI assistants competing with ChatGPT and Claude.
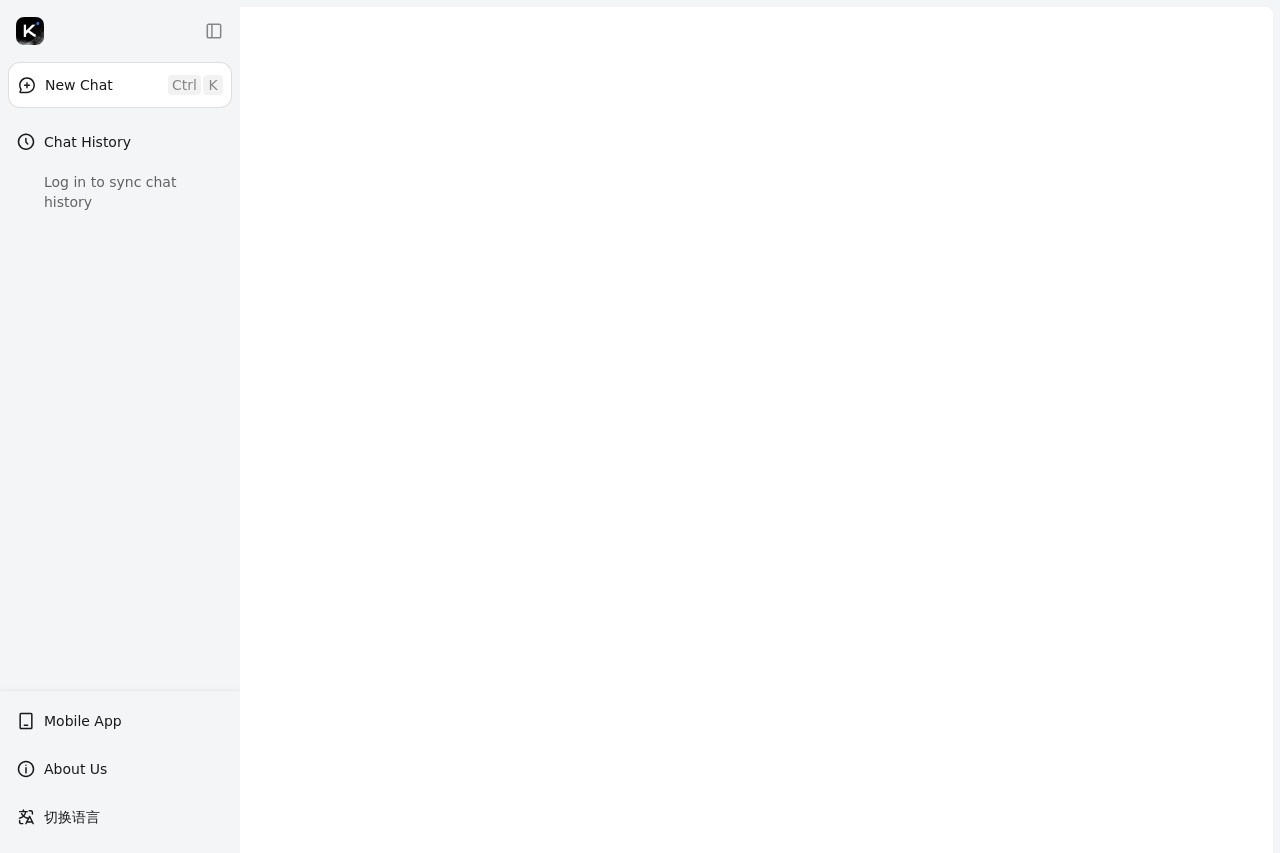
10B Beats 200B! StepFun Open-Sources Vision-Language SOTA Model: Step3-VL-10B
Chinese AI startup StepFun has open-sourced Step3-VL-10B, a groundbreaking 10-billion parameter vision-language model that outperforms models 20x its size. Achieving state-of-the-art results across multiple benchmarks, this release challenges the "bigger is better" paradigm and democratizes access to cutting-edge multimodal AI capabilities.
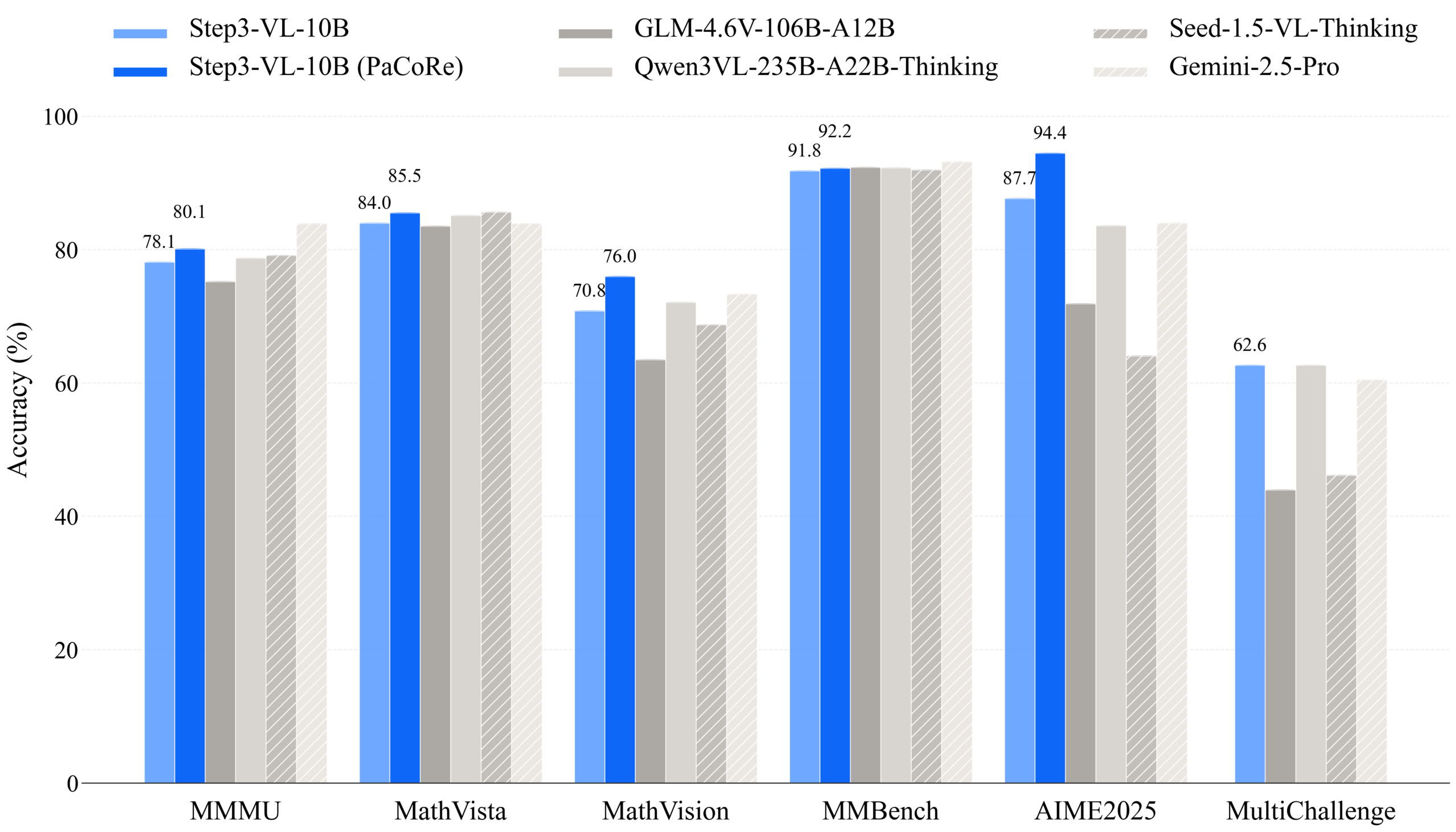
Step-Audio 2.1 Claims Global Audio Evaluation Crown
China's Steptok AI has made a significant leap in voice AI with its latest Step-Audio 2.1 model, which has reportedly achieved top-tier scores in multiple global audio understanding benchmarks, showcasing its advancements in end-to-end architecture and reasoning capabilities
Google Veo 3.1 Elevates AI Video with Consistency, Native Portrait Mode, and 4K Upscaling
Google's Veo 3.1 video generation model receives a major update, introducing breakthrough improvements in multi-scene consistency, native vertical (9:16) video support, and professional-grade 4K upscaling. These features are now integrated into Google's ecosystem including Gemini, YouTube Shorts, and Vertex AI, empowering both casual creators and enterprises to produce high-quality, narrative-driven video content with unprecedented control.







