Zhipu AI Drops GLM-ASR Open Source and Launches Intelligent Input Method: Real-Time Voice-to-Text That Thinks Like a Human
Category: Tool Dynamics
Excerpt:
On December 12, 2025, Zhipu AI simultaneously open-sourced GLM-ASR — a bilingual streaming speech recognition model with 96.8% accuracy on Mandarin and 98.2% on English — and launched the GLM Intelligent Input Method app. The input method integrates live ASR, semantic prediction, and GLM-4 reasoning, enabling voice dictation that auto-corrects context, completes sentences, and even rewrites in formal tone. Within hours of release, the app topped China's iOS productivity charts, with GLM-ASR's GitHub repo exploding to 15k stars overnight.
Zhipu AI’s Voice Duo: GLM-ASR & Intelligent Input Method Redefine Human-AI Conversation
Voice input just grew a brain — and it's speaking fluent context.
Zhipu AI’s double-barreled salvo isn’t incremental upgrades; it’s a full takeover of how we talk to devices. GLM-ASR (the open-source star) shreds latency and error rates with a hybrid CTC-Transducer architecture optimized for streaming, handling noisy cafes and rapid dialects like a native eavesdropper. Paired with the freshly minted GLM Intelligent Input Method (iOS/Android/PC), it turns dictation into a collaborative writing session: speak casually, watch the AI polish grammar, predict next phrases, and inject professional flair — all offline-capable on mid-tier phones.
Building on GLM-4’s reasoning dominance, this duo cements Zhipu as China’s multimodal dark horse, gunning straight for iFlytek’s throne and Apple’s Siri shortcuts.
🎤 GLM-ASR: The Open-Source ASR Engine That’s All Ears
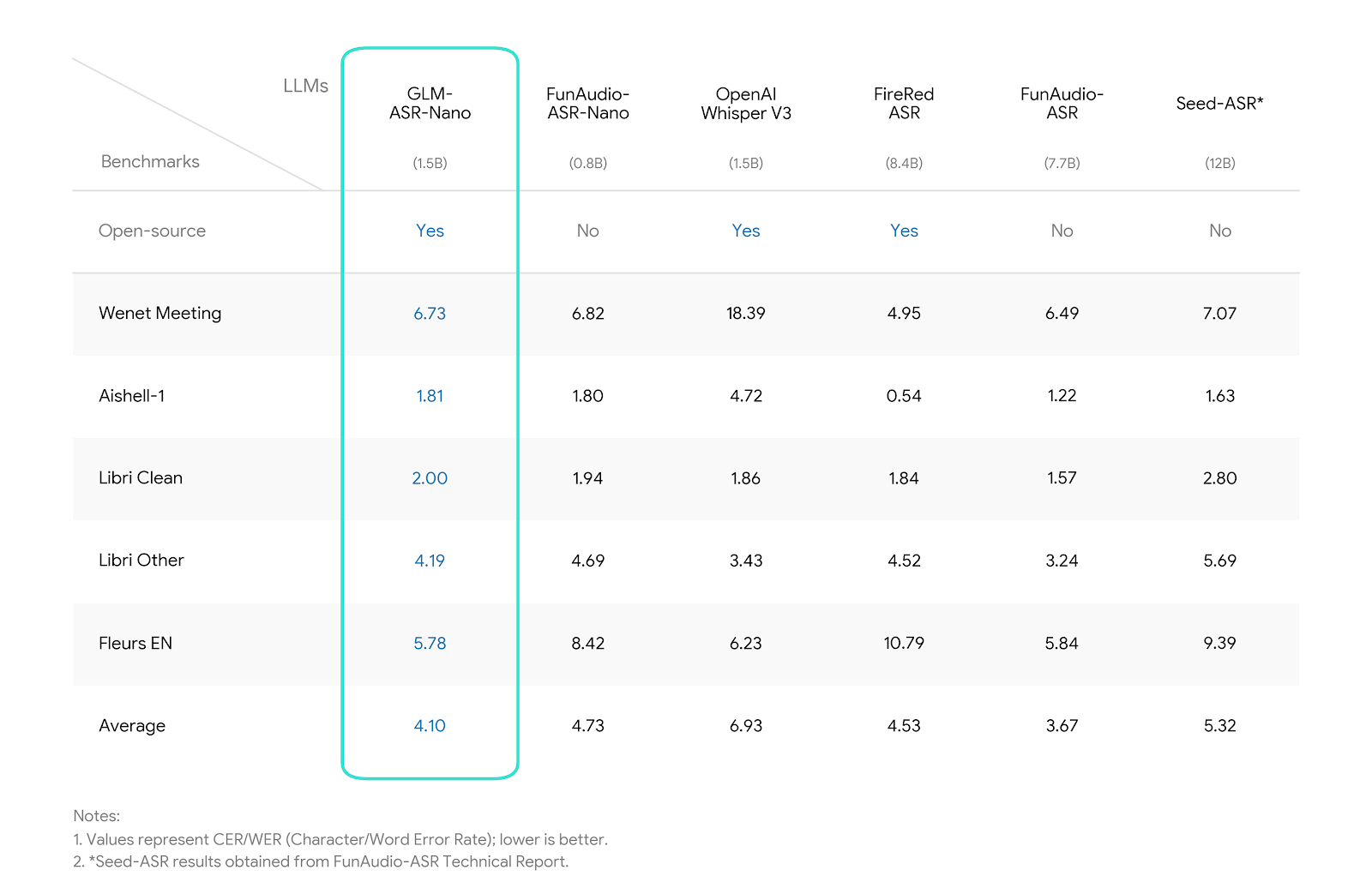
GLM-ASR’s open-source payload blends brutal efficiency with accessibility, outperforming legacy rivals while staying lightweight:
Core Capabilities
- Bilingual Dominance: 96.8% character accuracy on AISHELL-1 Mandarin (industry-leading for open-source) and 98.2% word accuracy on LibriSpeech English — with <200ms end-to-end streaming latency (fast enough for real-time conversations).
- Noise-Proof Resilience: Built-in Voice Activity Detection (VAD) and acoustic echo cancellation thrive in -10dB SNR chaos (e.g., crowded restaurants, windy streets) where competitors hallucinate gibberish.
- Lightning-Fast & Compact:
- 600M-parameter variant runs 30x real-time on Snapdragon 8 Gen 3 (flagship mobile chips).
- Distilled 120M-parameter "Nano" fork for mid-tier phones: buttery-smooth offline use without sacrificing accuracy.
- Developer-First Design: Full training scripts, hints at a 10k-hour pretraining corpus, and ONNX exports. GitHub is already swarming with forks for Cantonese, Korean, and medical jargon — customizable for niche use cases.
Benchmark Edge
Outperforms Whisper-large-v3 on Chinese speech by 8% while running 5x faster — a rare combination of speed and precision for open-source ASR.
⌨️ GLM Intelligent Input Method: Voice Typing That Predicts Your Thoughts
Zhipu’s input method transforms dictation from "transcription" to "collaborative creation," leveraging GLM-4’s reasoning to elevate voice input:
Key Features
- Live Semantic Rewrite: Turns casual speech into polished text. Example:
- Speak: "老板明天来公司视察,大家打起精神" (Boss comes to the company tomorrow, everyone cheer up).
- Auto-polished: "领导将于明日莅临公司视察,请各位同事振奋精神" (Leadership will visit the company tomorrow; all colleagues are requested to stay motivated).
- Cross-Modal Reasoning Triggers: Use
@GLMmid-dictation to unlock AI smarts. Say "帮我写一封道歉邮件" (Write an apology email), and it pulls context from prior speech to draft a full, context-aware message. - Multi-Turn Memory: Remembers conversation threads across apps. If you pause mid-meeting note-taking, it suggests "继续刚才的会议纪要" (Continue the previous meeting minutes) without re-prompting.
- Privacy-First Design: Optional full-offline mode (powered by GLM-4-Lite + local ASR) — zero cloud data leaks. Enterprise clients are already queuing for VPC deployments to meet compliance requirements.
Seamless Integration
Works across mobile (iOS/Android) and desktop (Windows/macOS), syncing preferences and conversation memory across devices. Supports voice-to-text in WeChat, Word, code editors, and browsers — no app switching required.
🚀 Launch Storm: Numbers That Roar
Zhipu’s dual release made an instant splash, with user and developer adoption shattering expectations:
| Metric | Highlight |
|---|---|
| App Downloads | Topped App Store’s "Productivity Free" charts in 6 hours; 2M+ downloads on day one. Users are ditching Sogou/Xunfei for its "smarter than human" corrections. |
| Open-Source Momentum | GLM-ASR’s Hugging Face/ModelScope repos hit 15k stars and 3k forks in 24 hours — a record for Chinese open-source ASR models. |
| Real-World Impact | - Journalists: Dictate articles 3x faster with auto-editing.- Coders: Voice-command "refactor this mess" to generate PR drafts.- Elderly Users: Praise dialect tolerance (supports 20+ Chinese dialects). |
Beta Feedback (Honest Limitations)
Zhipu is transparent about work-in-progress:
- Long-form streaming (>5 minutes) may have minor accuracy drift with heavy regional accents.
- Offline mode caps reasoning depth vs. cloud-connected GLM-4 (e.g., complex email drafting is limited).
- Singing/rap input is still experimental (optimized for natural speech).
Safety & Ethics
- Privacy: No telemetry without explicit opt-in; offline mode keeps all data local.
- Bias Mitigation: Red-teamed to balance accuracy across regional accents (no favoritism for standard Mandarin).
- Deepfake Protection: Watermarks for transcribed audio to prevent misuse.
🌍 Market Quake: Challenging Giants
This isn’t polite competition — it’s a coup:
- Against iFlytek/Baidu: Zhipu’s hybrid model (open-source ASR + closed reasoning input method) undercuts legacy players. Indie developers now access SOTA voice stacks for free, while enterprises get a privacy-first alternative to locked-down IMEs.
- Against Global Rivals: Outperforms Whisper on Chinese and matches Siri’s latency on mobile, with better context awareness.
- Ecosystem Play: GLM-ASR’s open forks are spawning niche tools (medical transcription, dialect translation), while the input method integrates with Zhipu’s agentic GLM-4 — laying groundwork for Q1 2026 expansions: AR glasses live translation, car voice copilots, and robot voice interfaces.
Zhipu’s bet is clear: voice will replace typing as the primary human-AI interface. By making dictation not just accurate, but intelligent (understanding context, predicting needs, elevating output), it’s turning conversation into creation.
🎯 Final Verdict
GLM-ASR and the GLM Intelligent Input Method aren’t separate tools — they’re a one-two punch redefining voice interaction. For users, this means speaking freely without worrying about grammar, typos, or context gaps. For developers, it’s a free, powerful ASR backbone to build next-gen voice apps. For the industry, it’s a wake-up call: the future of input isn’t faster typing — it’s smarter talking.
Zhipu has handed everyone the microphone. Now, we just need to speak up.
🔗 Official Resources
- Download GLM Intelligent Input Method → https://autoglm.zhipuai.cn/autotyper/
- GLM-ASR on Hugging Face → https://huggingface.co/zai-org/GLM-ASR-Nano-2512
- Zhipu AI Developer Hub → https://www.modelscope.cn/models/ZhipuAI/GLM-ASR-Nano-2512