Google DeepMind Unveils AlphaFold 4: Mastering Multi-Molecular Complex Folding with 98.7% Accuracy and 10x Faster Inference
On December 15, 2025, Google DeepMind officially launched AlphaFold 4 — the breakthrough evolution that finally cracks reliable prediction of large multi-molecular complexes. Boasting 98.7% interface accuracy on challenging heteromeric assemblies, native support for proteins + ligands + nucleic acids + ions in one unified model, and a staggering 10x computational efficiency boost, AlphaFold 4 Pro is rolling out via the new AlphaFold Server 2.0 and Isomorphic Labs platform. Early benchmarks show it obliterating previous limitations, enabling routine modeling of drug-target complexes that stumped AlphaFold 3.
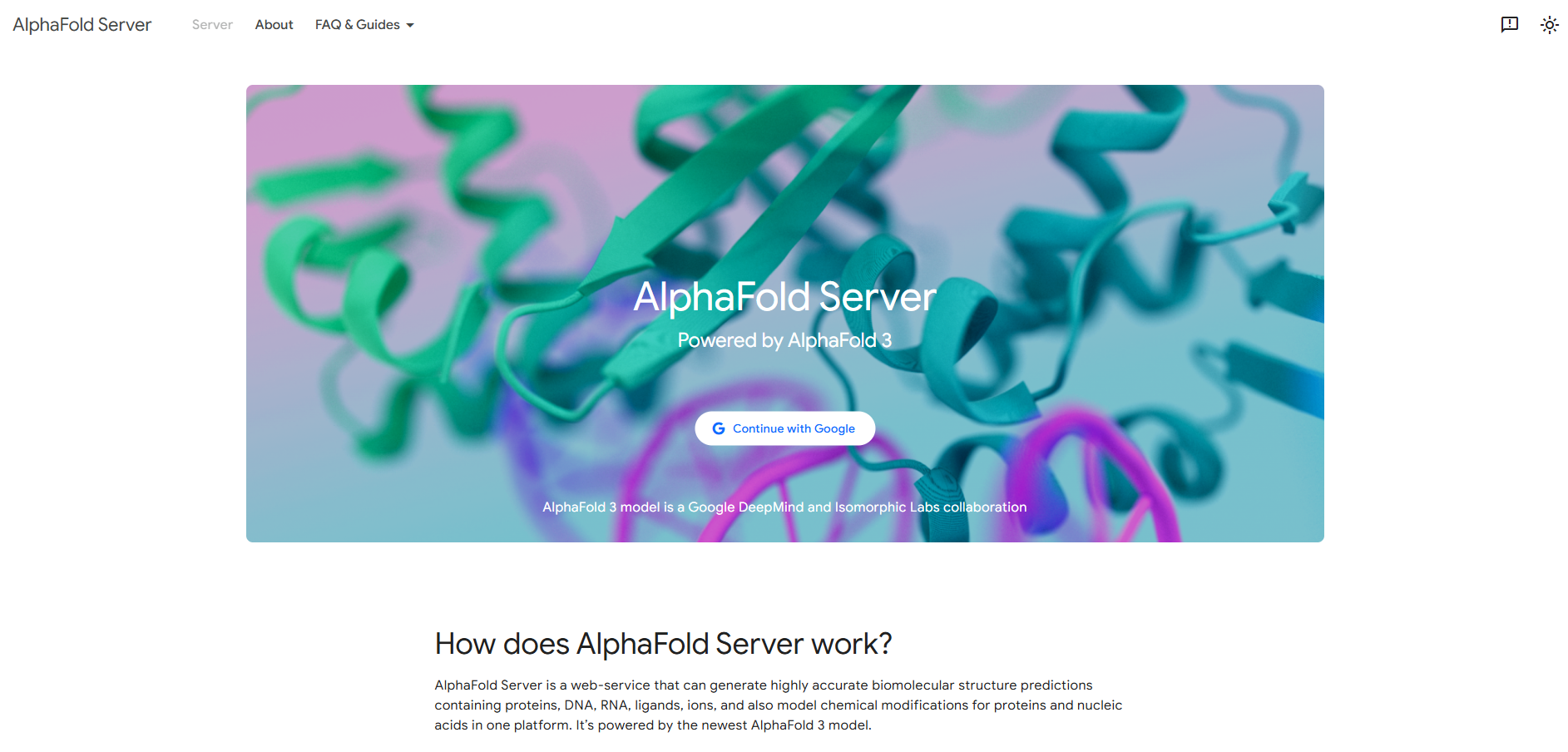
Zhipu AI Open-Sources GLM-4.7: The New King of Open-Source Models Claims Global Coding Throne with SOTA Reasoning and Agentic Execution
On December 22, 2025, Zhipu AI unleashed GLM-4.7 — its latest flagship open-source model that storms to the top of global open-source leaderboards. Packing revolutionary "Preserved Thinking" for multi-turn consistency, interleaved reasoning modes, and massive leaps in coding + tool use, it hits open-source SOTA on LiveCodeBench (84.9%), τ²-Bench (87.4%), and HLE (42.8%) — outperforming Claude Sonnet 4.5 in key agentic tasks while crushing long-context stability. Fully open-weights on Hugging Face, GLM-4.7 accelerates enterprise deployment, scientific research, and content pipelines at a fraction of proprietary costs.
Meta Unveils WorldGen: Revolutionary Text-to-3D System Generates Fully Explorable 50×50 Meter Interactive Worlds
Meta Reality Labs announced WorldGen on November 20, 2025 — a breakthrough research system that transforms a single text prompt into large-scale, navigable 3D environments spanning up to 50×50 meters. Combining procedural planning, diffusion-based reconstruction, and object-aware decomposition, WorldGen produces geometrically consistent, fully textured scenes with built-in navmeshes for real-time exploration in Unity or Unreal Engine. While generation takes minutes and real-time rendering achieves sub-200ms latency in engines, this marks a massive leap toward AI-powered world-building for gaming, VR, and simulation.

Google Drops 2025 Research Recap: 8 Massive Breakthroughs from Long-Context Mastery to Multimodal Reasoning, Solidifying Its AI Foundations
On December 23, 2025, Google published its annual research review, spotlighting eight pivotal breakthrough areas that defined the year for Google Research and DeepMind. From revolutionary long-context processing and native multimodal understanding to agentic systems, model efficiency, generative media, scientific discovery, quantum leaps, and responsible AI frameworks, these advances — powered by milestones like Gemini 3 and Gemma 3 — transformed AI from experimental tool to everyday utility, with real-world deployments accelerating innovation across science, productivity, and global challenges.
Microsoft × PKU × SJTU Unveil QFANG: The Breakthrough Scientific LLM That Bridges Computational Design to Lab Execution in Materials Synthesis
On December 16, 2025, a collaborative team from Microsoft Research Asia, Peking University, and Shanghai Jiao Tong University released QFANG — a groundbreaking large language model specialized for organic and inorganic materials synthesis procedure generation. Trained on over 900,000 reaction-procedure pairs with chemistry-guided reasoning and reinforcement learning from verifiable rewards, QFANG achieves +22% accuracy in synthesis prediction and slashes R&D cycles by 40% in early lab tests. This closes the infamous "compute-to-lab" gap, turning in-silico designs into executable experiments with unprecedented reliability.

MiniMax Hailuo Video Team Drops VTP: The First Open-Source Scalable Visual Tokenizer Pre-Training Framework — Revolutionizing Generative Video Pipelines
On December 16, 2025, the MiniMax Hailuo Video team officially open-sourced VTP (Visual Tokenizer Pre-training) — a groundbreaking unified framework for pre-training visual tokenizers optimized for downstream generation tasks. By jointly optimizing contrastive, self-supervised, and reconstruction losses, VTP creates semantic-rich latent spaces that scale dramatically better than traditional autoencoders, delivering 65.8% FID gains in DiT-based video/image generation with just more pre-training FLOPs. Models (0.2B-0.3B) and code are now live on GitHub and Hugging Face, empowering the community to build next-gen Hailuo-level video models without starting from scratch.

Moore Threads' LiteGS Takes Silver at SIGGRAPH Asia 2025: China's Homegrown 3DGS Tech Accelerates Training 10x While Open-Sourcing the Future of Reconstruction
On December 17, 2025, Moore Threads stunned the graphics world by clinching silver in the 3D Gaussian Splatting Reconstruction Challenge at SIGGRAPH Asia 2025 in Hong Kong. Their self-developed LiteGS framework — a full-stack co-optimized powerhouse — delivers up to 10.8x faster training with half the parameters compared to baselines, while lightweight variants hit equivalent quality using just 10% training time and 20% params. Fully open-sourced on GitHub today, LiteGS is igniting global collaboration in real-time 3D reconstruction for AR/VR, robotics, and beyond.
Finland's VTT Unveils MISEL Breakthrough: Bio-Inspired Edge Vision System Lets Robots Operate Offline in Disaster Zones — No Network, No Heavy Batteries Needed
VTT Technical Research Centre of Finland announced the completion of the EU-funded MISEL project on December 11, 2025 — delivering a neuromorphic machine vision system that mimics human retina-brain cooperation via embedded low-power circuits. This edge-computing marvel enables drones and robots to perceive, interpret, and act autonomously in harsh environments like post-earthquake rubble, slashing energy use while ditching cloud dependency. Early prototypes promise fruit-fly-level efficiency, with applications spanning rescue ops to industrial monitoring — a game-changer for embodied AI in real-world chaos.
University of Waterloo Unveils SubTrack++: The Breakthrough Training Method That Slashes LLM Pre-Training Time by 50% While Boosting Accuracy
Researchers at the University of Waterloo launched SubTrack++ on December 9, 2025 — a revolutionary gradient subspace tracking technique that cuts large language model pre-training time by up to 50% (with arXiv benchmarks showing even 65% gains), maintains identical memory footprints, and surpasses state-of-the-art accuracy. Developed in the Critical Machine Learning Lab, this open-approach democratizes LLM building by slashing costs and energy use, with the paper set for spotlight at NeurIPS 2025. Early evals on 1B-parameter models confirm SOTA convergence, paving the way for greener, more accessible frontier AI.

Mistral AI Unleashes Mistral 3: The Apache 2.0 Open-Source Powerhouse Family Crushing Proprietary Giants with Edge-to-Frontier Multimodal Might
Mistral AI launched the Mistral 3 series on December 2, 2025 — a blockbuster family of 10 fully open-weight multimodal models under the permissive Apache 2.0 license, spanning Ministral 3 (3B/8B/14B dense variants in base, instruct, and reasoning flavors) to the beastly Mistral Large 3 (675B total params MoE with 41B active). Optimized for everything from drones to datacenters, these models nail image understanding, non-English prowess, and SOTA efficiency, debuting at #2 on LMSYS Arena OSS non-reasoning while slashing token output by 10x in real-world chats. This full-line return to unrestricted commercial openness is a direct gut punch to closed ecosystems like OpenAI and Google.

SenseTime Unleashes NEO Architecture: The Native Multimodal Revolution That Fuses Vision and Language at the Core — Open-Sourced to Shatter Efficiency Barriers
SenseTime, in collaboration with Nanyang Technological University's S-Lab, launched the NEO architecture on December 5, 2025 — the world's first scalable, open-source native Vision-Language Model (VLM) framework that ditches modular "Frankenstein" designs for true bottom-up fusion. Featuring pixel-direct embedding, Native-RoPE for spatiotemporal harmony, and hybrid attention mechanisms, NEO achieves SOTA performance on benchmarks like MMMU and MMBench with 90% less training data than GPT-4V. The 2B and 9B models are now live on GitHub, with video/3D extensions slated for Q1 2026, igniting a paradigm shift toward edge-deployable multimodal brains.

Alibaba Open-Sources Z-Image: The 6B-Parameter Efficiency Beast That Matches 20B+ Closed-Source Titans in Photorealism and Speed
Alibaba's Tongyi Lab dropped Z-Image on November 26, 2025 — a revolutionary 6B-parameter open-source text-to-image model that's now live on Hugging Face under Apache 2.0. Featuring Single-Stream Diffusion Transformer (S3-DiT) architecture, it generates stunning 1024x1024 images in just 8 steps with sub-second latency on consumer GPUs (16GB VRAM), supporting bilingual text rendering and complex prompts. Outpacing Midjourney V7 and DALL-E 3 in human preference Elo scores (1,038 on AI Arena), Z-Image-Turbo variant slashes costs by 3x while delivering SOTA visual quality — a lightweight lightning bolt for devs, creators, and edge AI.

- Previous Page
- 1
- 2
- 3
- 4
- Total 4 pages

Meta Completes Acquisition of AI Agent Startup Dreamer, Bringing Top Tech Talent to Superintelligence Labs
03/25/2026
OpenAI Acquires Astral: A Strategic Leap into Python Developer Tooling
03/25/2026
OpenAI Shuts Down Sora, Cancels $1B Disney Deal: Strategic Pivot to Enterprise Productivity Tools
03/25/2026
Alibaba Launches "Enterprise-Grade Lobster" Accio Work: AI Agent Builds Online Stores in 30 Minutes
03/25/2026
Video content at the speed of social media — without hiring a production team
03/25/2026
Professional videos without cameras, actors, or $20,000 production budgets
03/25/2026
Enterprise Video Content at Scale: The AI Video Workflow That Replaces Your Production Team
03/25/2026
Elon Musk Unveils $25B Terafab Chip Project: Sequoia Partner Declares "xAI Will Win"
03/24/2026
Dash0 Raises $110M at $1B Valuation: OpenTelemetry-Native Platform Challenges Datadog with AI Agents
03/24/2026